

DrissionPage 是一个基于 python 的网页自动化工具。
它既能控制浏览器,也能收发数据包,还能把两者合而为一。
可兼顾浏览器自动化的便利性和 requests 的高效率。
它功能强大,内置无数人性化设计和便捷功能。
它的语法简洁而优雅,代码量少,对新手友好。
概述
SessionPage
用于收发数据包的页面对象,只能收发数据包,不能控制浏览器。
ChromiumPage
用于控制浏览器的对象。除了控制一个页面,还能对浏览器整体进行操作,如调整窗口大小位置、管理文件下载、增删标签页等。
WebPage
整合 SessionPage 和 ChromiumPage 两者功能的页面元素,拥有两者加起来的全部功能。运行时有 s 和 d 两种模式,能够在两种模式间同步登录信息。
使用 SessionPage 爬取网易云热歌榜
顾名思义,SessionPage 是一个使用 Session(requests 库)对象的页面,它使用 POM 模式封装了网络连接和 html 解析功能,使收发数据包也可以像操作页面一样便利。
代码
# 导入
from DrissionPage import SessionPage
from DataRecorder import Recorder
# 创建页面对象
page = SessionPage()
# 创建记录器对象
recorder = Recorder('music_data.csv')
# 请求网站url 网易云音乐 热歌榜 top200
page.get('https://music.163.com/discover/toplist?id=3778678')
# 遍历页面上所有 li 元素 获取热歌榜Top200的歌名和url
for index,li in enumerate(page.eles('xpath://ul[@class="f-hide"]/li')):
music_ranking = index + 1 # 排名
music_title = li.ele('tag:a').text
music_url = li('tag:a').attr('href')
# 请求歌曲url 获取歌手姓名
page.get(music_url)
music_singer = page.ele('xpath://p[@class="des s-fc4"]/span').text
# print(music_ranking,music_title,music_singer)
# 写入到记录器
recorder.add_data((music_ranking,music_title,music_singer))
recorder.record()
运行
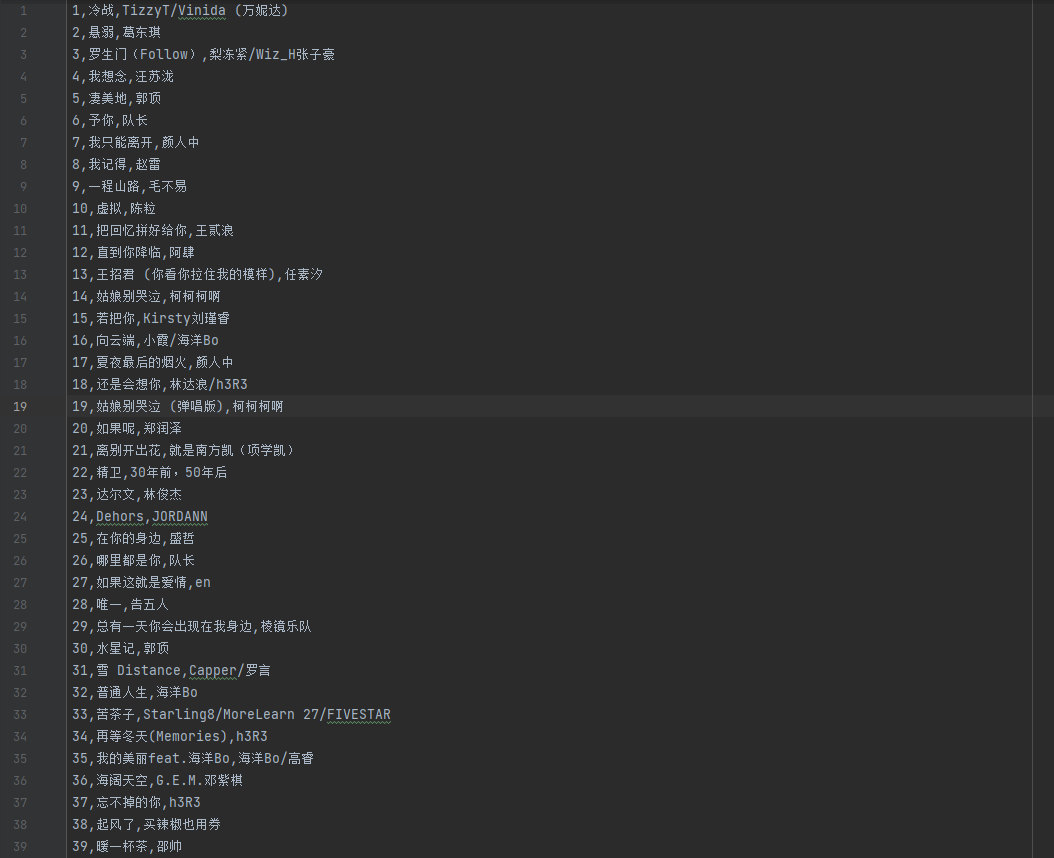
程序生成一个结果文件 data.csv,内容如下图:
获取资源前请仔细阅读一下声明:
重要提示
如有解压密码: 看下载页、看下载页、看下载页。
源码工具资源类具有可复制性: 建议具有一定思考和动手能力的用户购买。
请谨慎考虑: 小白用户和缺乏思考动手能力者不建议赞助。
虚拟商品购买须知: 虚拟类商品,一经打赏赞助,不支持退款。请谅解,谢谢合作!
声明: 本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。